|
Yuanhan (John) Zhang
Hi! I'm Yuanhan Zhang; here is the standard Chinese pronunciation of my given name:
Yuanhan.
I am a final year PhD student at
MMLab@NTU,
supervised by Prof.
Ziwei Liu.
My research interests lie in computer vision and deep learning. I focus on adapting foundation models—from vision to
multimodal—for real-world use: benchmarking model performance and adapting models via parameter-efficient tuning,
in-context learning, and instruction tuning.
Email (yuanhan002@e.ntu.edu.sg) /
Google Scholar /
Twitter /
GitHub
|

|
-
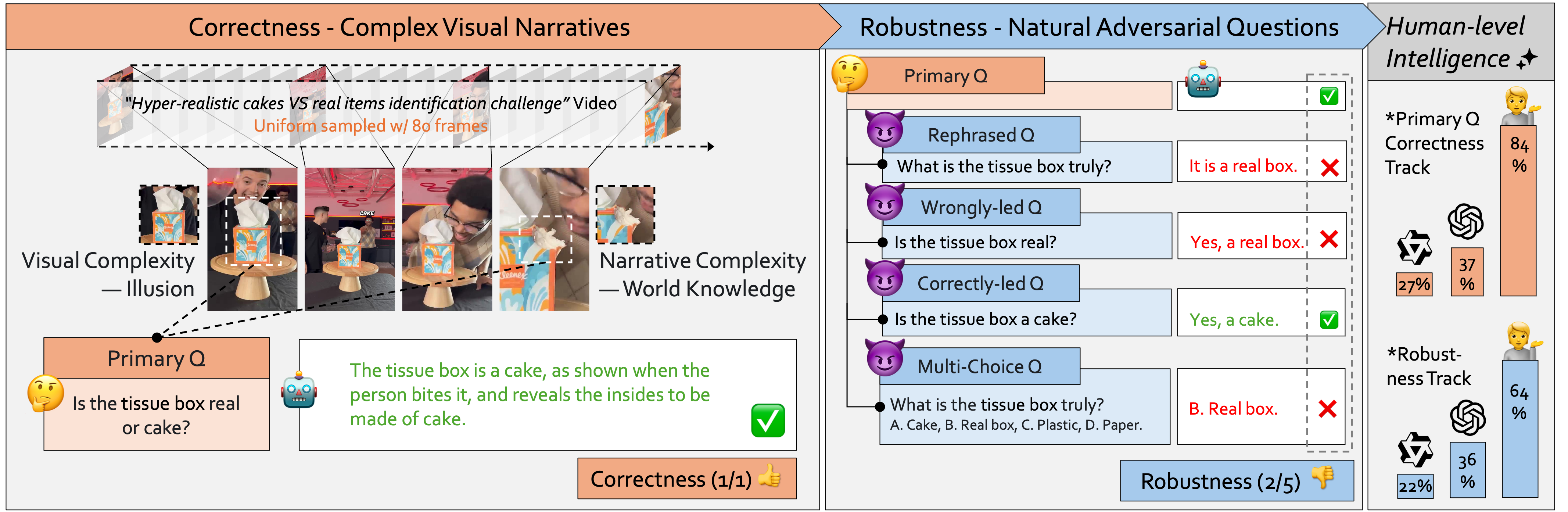
[2025-07] We release Video Thinking Test (📽️
Video-TT
📽️), a holistic benchmark to assess advanced reasoning and understanding correctness/robustness between MLLMs and humans.
Older News & Activities
|
|
Towards Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning and Understanding
Yuanhan Zhang*,
Yunice Chew*,
Yuhao Dong,
Aria Leo,
Bo Hu,
Ziwei Liu
ICCV, 2025
PDF /
Dataset and Code
A holistic benchmark to assess advanced reasoning and understanding correctness/robustness between MLLMs and humans.
|
|
|
|
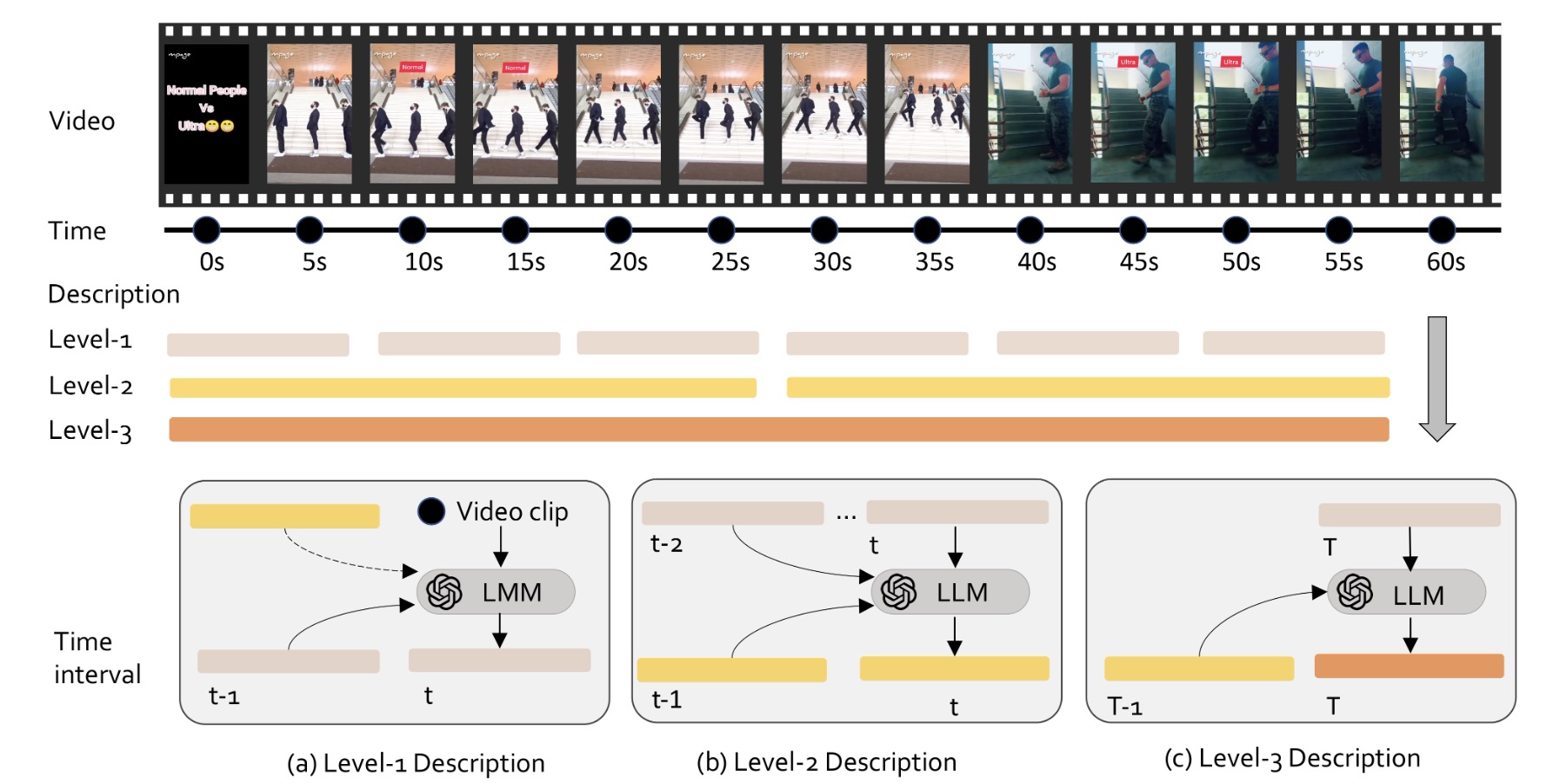
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang,
Jinming Wu,
Wei Li,
Bo Li,
Zejun Ma,
Ziwei Liu,
Chunyuan Li
TMLR, 2025
PDF /
Dataset, Model and Code

Fully open-sourced video LMM (code, model, and data) with competitive ability.
|
|
|
|
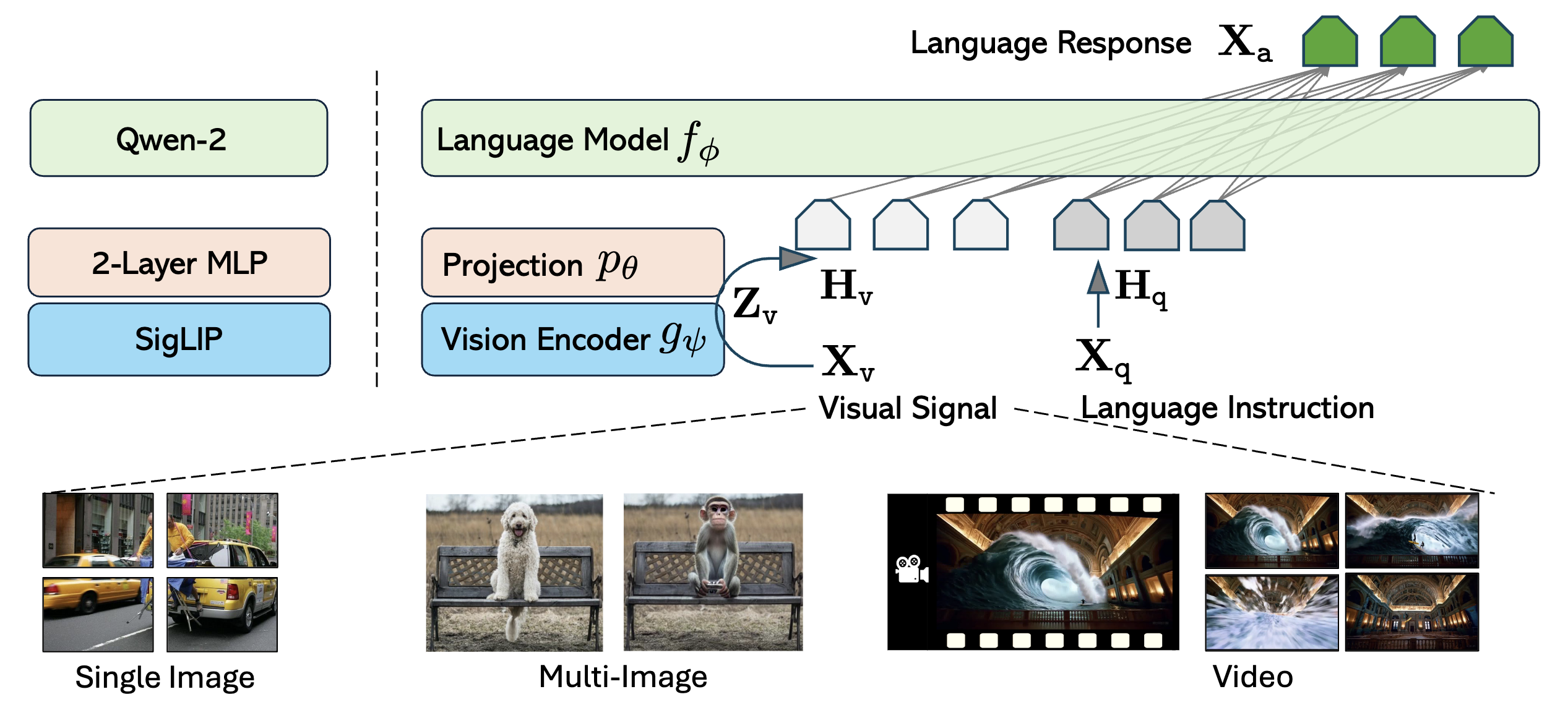
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li,
Yuanhan Zhang,
Dong Guo,
Renrui Zhang,
Feng Li,
Hao Zhang,
Kaichen Zhang,
Yanwei Li,
Ziwei Liu,
Chunyuan Li
TMLR, 2025
PDF /
Dataset and Code
A family of LMMs consolidating insights into data, models, and visual representations.
|
|
|
|
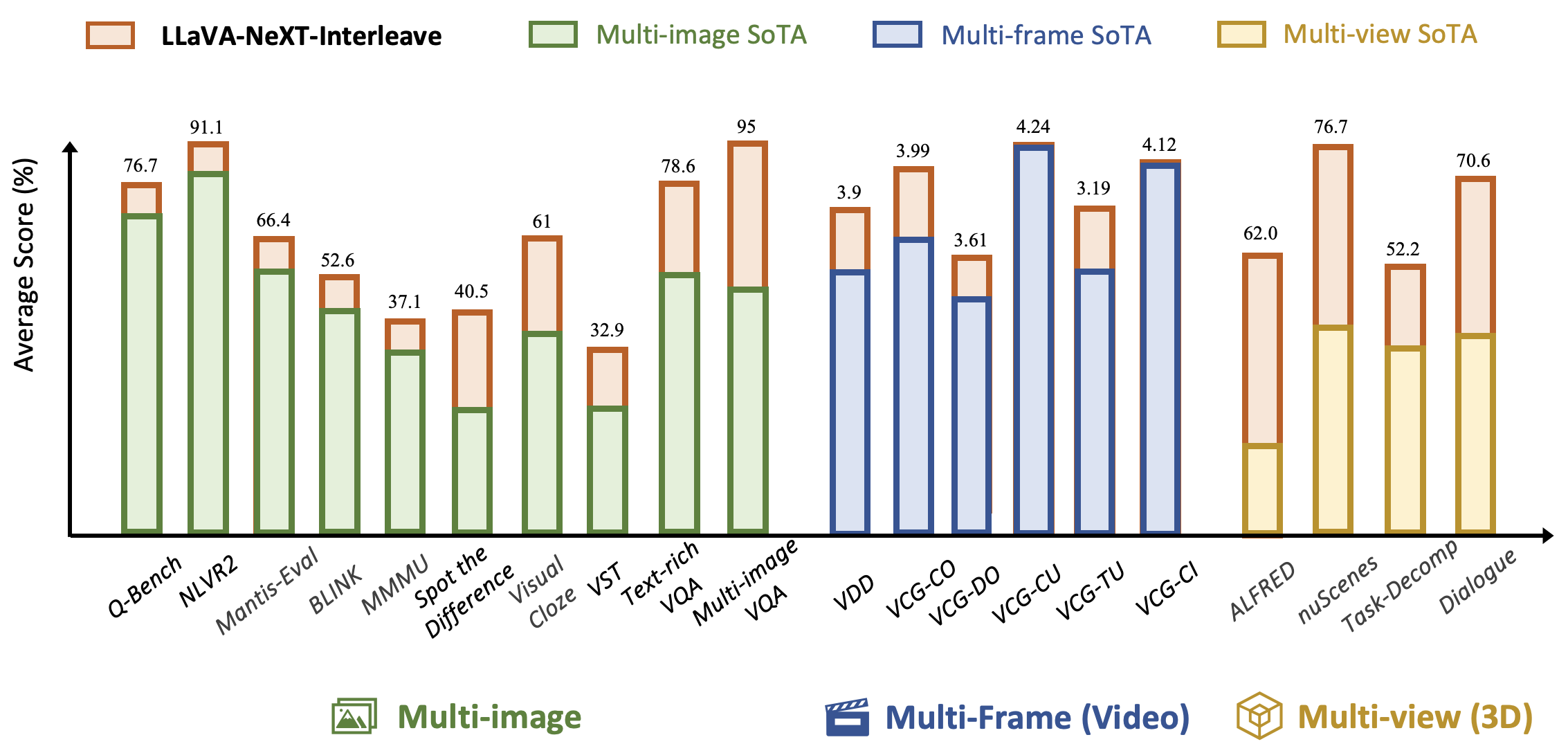
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li*,
Renrui Zhang*,
Hao Zhang*,
Yuanhan Zhang,
Bo Li,
Wei Li,
Zejun Ma
ICLR, 2025 (Spotlight)
PDF /
Dataset and Code
Tackling multi-image, video, and 3D in large multimodal models.
|
|
|
|
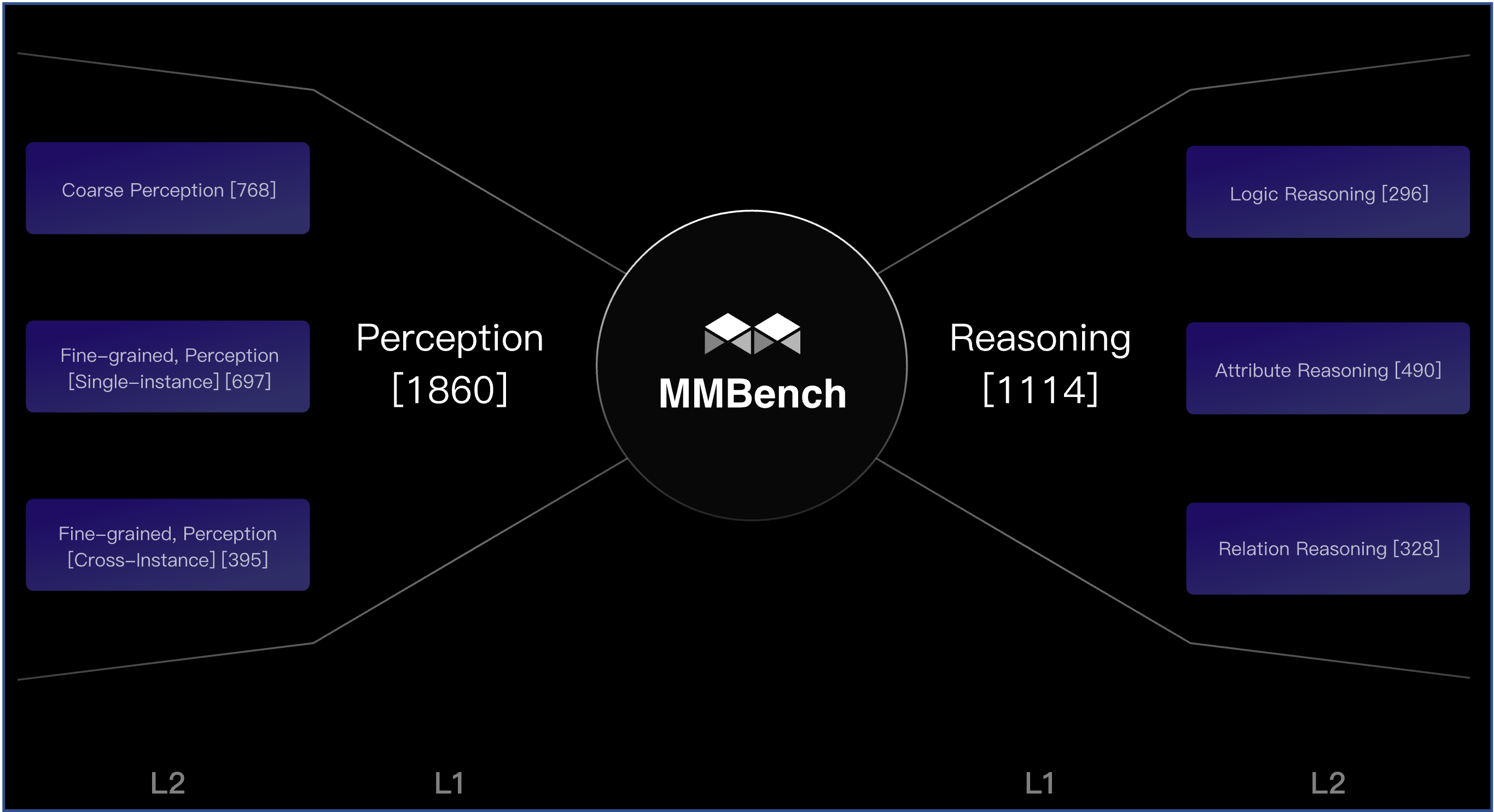
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu*,
Haodong Duan*,
Yuanhan Zhang*,
Bo Li*,
Songyang Zhang*,
Wangbo Zhao,
Yike Yuan,
Jiaqi Wang,
Conghui He,
Ziwei Liu,
Kai Chen,
Dahua Lin
ECCV, 2024 (Oral)
PDF /
Dataset and Code

Benchmarking 20 abilities of vision-language models.
|
|
|
|
Octopus: Embodied Vision-Language Programmer from Environmental Feedback
Jingkang Yang,
Yuhan Dong,
Shuai Liu,
Bo Li,
Ziyue Wang, Chencheng Jiang, Haoran Tan, Jiamu Kang,
Yuanhan Zhang,
Kaiyang Zhou,
Ziwei Liu
ECCV, 2024
PDF /
Dataset and Code

An embodied VLM trained with RLEF, strong at embodied visual planning and programming.
|
|
|
|
FunQA: Towards Surprising Video Comprehension
Binzhu Xie,
Sicheng Zhang,
Zitang Zhou,
Bo Li,
Yuanhan Zhang,
Jack Hessel,
Jingkang Yang,
Ziwei Liu
ECCV, 2024
PDF /
Dataset and Code

Benchmarks funny, creative, and magic videos for challenging video understanding.
|
|
|
|
Otter: A Multi-modal Model with In-context Instruction Tuning
Bo Li*,
Yuanhan Zhang*,
Liangyu Chen,
Jinghao Wan,
Fanyi Pu,
Jingkang Yang,
Chunyuan Li,
Ziwei Liu
TPAMI
PDF /
Dataset and Code

A vision-language model with in-context instruction tuning.
|
|
|
|
|
What Makes Good Examples for Visual In-Context Learning?
Yuanhan Zhang,
Kaiyang Zhou,
Ziwei Liu
NeurIPS, 2023
PDF /
Code

Retrieving prompts for visual in-context learning.
|
|
|
|
Learning without Forgetting for Vision-Language Models
Da-Wei Zhou,
Yuanhan Zhang,
Yan Wang,
Jingyi Ning,
Han-Jia Ye,
De-Chuan Zhan,
Ziwei Liu
TPAMI
PDF /
Code

Learning without forgetting for vision-language models.
|
|
|
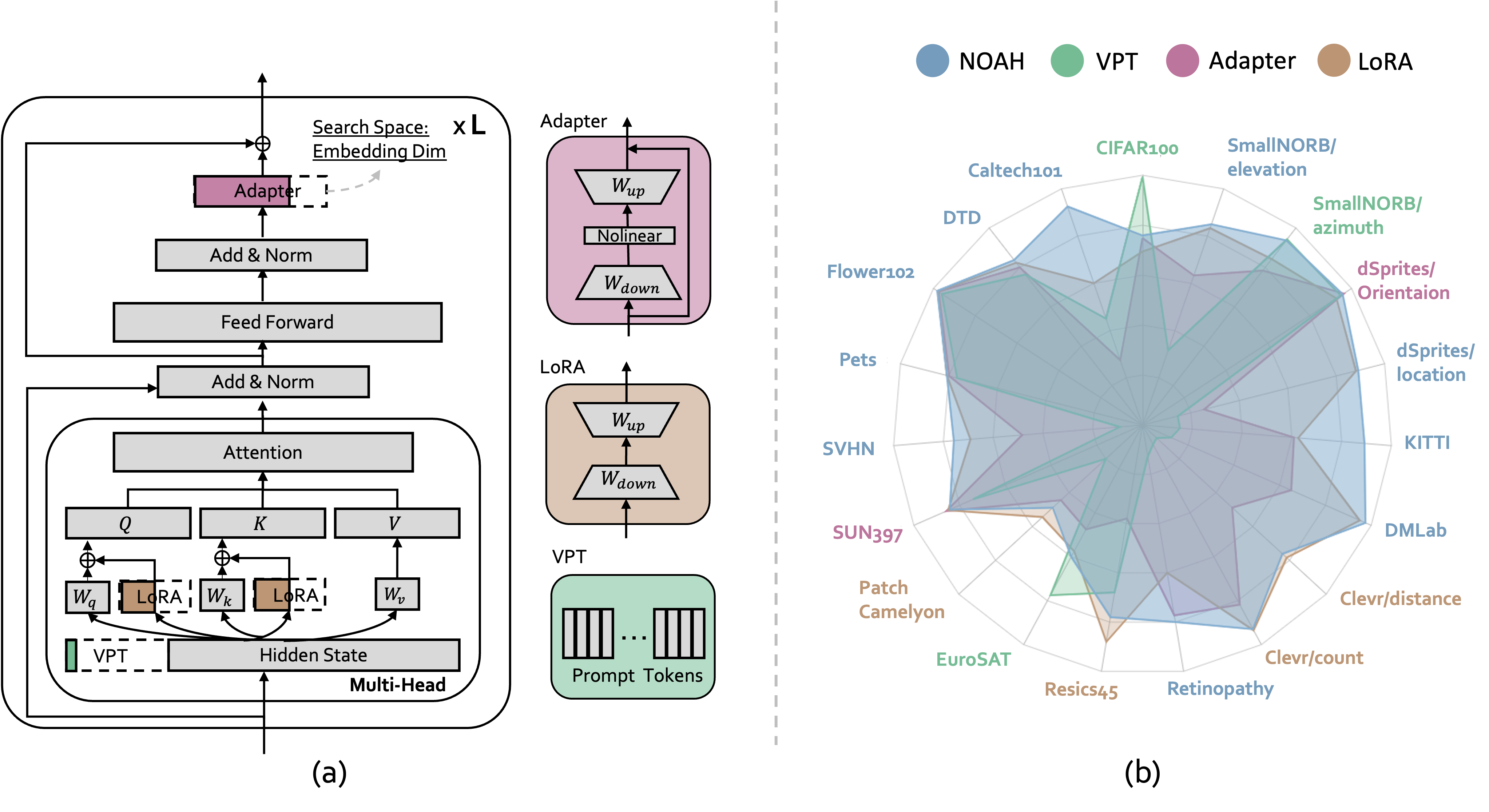
Neural Prompt Search
Yuanhan Zhang,
Kaiyang Zhou,
Ziwei Liu
TPAMI
PDF /
Project Page /
Code

Searching prompt modules for parameter-efficient transfer learning.
|
|
|
|
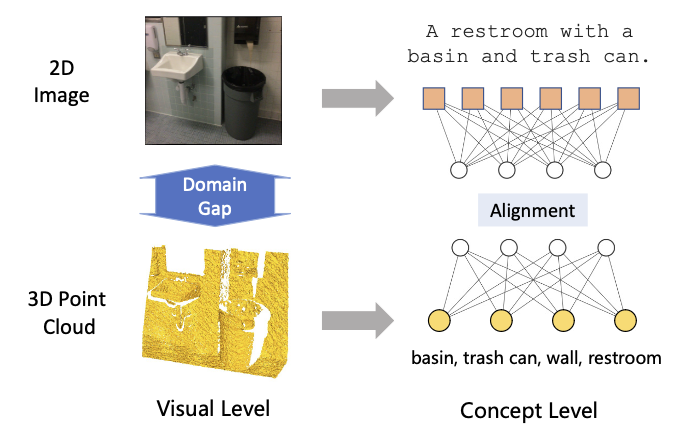
3D Point Cloud Pre-training with Knowledge Distillation from 2D Images?
Yuan Yao,
Yuanhan Zhang,
Zhenfei Yin,
Jiebo Luo,
Wanli Ouyang,
Xiaoshui Huang
ICME, 2023
PDF /
Code
3D point cloud pre-training with knowledge distillation from 2D images.
|
|
|
|
Benchmarking Omni-Vision Representation through the Lens of Visual Realms
Yuanhan Zhang,
Zhenfei Yin,
Jing Shao,
Ziwei Liu
ECCV, 2022
PDF /
Project Page /
Leaderboard /
Challenge: ImageNet-1k Pretrain Track /
Challenge: Open-Pretrain Track /
Dataset and Code

New benchmark for evaluating vision foundation models; supervised contrastive learning framework.
|
|
|
|
CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
Yuanhan Zhang,
Zhenfei Yin,
Yidong Li,
Guojun Yin,
Junjie Yan,
Jing Shao,
Ziwei Liu
ECCV, 2020
PDF /
Dataset /
Demo /
Code

Large-scale face anti-spoofing dataset.
|
Last updated in Aug. 2025.
Homepage credits:
Jon Barron.
|
|